Matematiska funktioner

Grafik som beskriver Hyperbolastic Type I-funktionen med varierande parametervärden.

Grafik som beskriver Hyperbolastic Type I-funktionen med varierande parametervärden.

Grafik som beskriver Hyperbolastic Type II-funktionen med varierande parametervärden.

Grafik som beskriver Hyperbolastic Type II-funktionen med varierande parametervärden.

Grafik som beskriver Hyperbolastic Type III-funktionen med varierande parametervärden.

Grafik som beskriver den hyperbolastiska kumulativa distributionsfunktionen av typ III med varierande parametervärden.

Grafik som beskriver den hyperbolastiska sannolikhetstäthetsfunktionen av typ III med varierande parametervärden.
Hyperbolastiska funktioner , även kända som hyperbolastiska tillväxtmodeller , är matematiska funktioner som används i medicinsk statistisk modellering . Dessa modeller utvecklades ursprungligen för att fånga tillväxtdynamiken hos flercelliga tumörsfärer och introducerades 2005 av Mohammad Tabatabai, David Williams och Zoran Bursac. Precisionen hos hyperbolastiska funktioner vid modellering av verkliga problem beror något på deras flexibilitet i deras böjningspunkt. Dessa funktioner kan användas i en mängd olika modelleringsproblem såsom tumörtillväxt, stamcellsproliferation , farmakinetik, cancertillväxt, sigmoidaktiveringsfunktion i neurala nätverk och epidemiologisk sjukdomsprogression eller regression.
De hyperbolastiska funktionerna kan modellera både tillväxt- och avklingningskurvor tills den når bärkraft . På grund av sin flexibilitet har dessa modeller olika tillämpningar inom det medicinska området, med förmågan att fånga sjukdomsprogression med en mellanliggande behandling. Som figurerna indikerar hyperbolastiska funktioner passa en sigmoidal kurva som indikerar att den lägsta hastigheten inträffar i de tidiga och sena stadierna. Förutom de uppvisande sigmoidala formerna kan den också rymma bifasiska situationer där medicinska ingrepp bromsar eller vänder sjukdomsprogression; men när effekten av behandlingen försvinner, kommer sjukdomen att börja den andra fasen av sin progression tills den når sin horisontella asymptot.
En av de viktigaste egenskaperna som dessa funktioner har är att de inte bara kan passa sigmoidala former, utan kan också modellera bifasiska tillväxtmönster som andra klassiska sigmoidala kurvor inte kan modellera tillräckligt. Denna särskiljande egenskap har fördelaktiga tillämpningar inom olika områden, inklusive medicin, biologi, ekonomi, ingenjörsvetenskap, agronomi och datorstödd systemteori.
Funktion H1
Ekvationen för hyperbolastisk hastighet av typ I, betecknad H1, ges av

där  är valfritt reellt tal och
är valfritt reellt tal och  är populationsstorleken vid . Parametern
är populationsstorleken vid . Parametern  representerar bärförmåga, och parametrarna
representerar bärförmåga, och parametrarna  och
och  representerar tillsammans tillväxthastighet. Parametern anger avståndet från en symmetrisk sigmoidal kurva. Att lösa den hyperbolastiska hastighetsekvationen av typ I för ger
representerar tillsammans tillväxthastighet. Parametern anger avståndet från en symmetrisk sigmoidal kurva. Att lösa den hyperbolastiska hastighetsekvationen av typ I för ger

där  är den inversa hyperboliska sinusfunktionen . Om man vill använda initialvillkoret
är den inversa hyperboliska sinusfunktionen . Om man vill använda initialvillkoret  , då kan
, då kan  uttryckas som
uttryckas som
-
 .
.
Om  minskar till
minskar till
-
 .
.
Den hyperbolastiska funktionen av typ I generaliserar den logistiska funktionen . Om parametrarna  , så skulle det bli en logistisk funktion. Denna funktion
, så skulle det bli en logistisk funktion. Denna funktion  är en hyperbolastisk funktion av typ I . Standard hyperbolastisk funktion av typ I är
är en hyperbolastisk funktion av typ I . Standard hyperbolastisk funktion av typ I är
-
 .
.
Funktion H2
Hyperbolastisk hastighetsekvation av typ II, betecknad med H2, definieras som

där  är den hyperboliska tangentfunktionen , är bärförmågan, och både och
är den hyperboliska tangentfunktionen , är bärförmågan, och både och  bestämmer tillsammans tillväxthastigheten . Dessutom representerar parametern
bestämmer tillsammans tillväxthastigheten . Dessutom representerar parametern  acceleration i tidsförloppet. Att lösa hyperbolastic rate-funktionen av typ II för ger
acceleration i tidsförloppet. Att lösa hyperbolastic rate-funktionen av typ II för ger
-
 .
.
Om man vill använda initialvillkoret  så kan
så kan
-
 .
.
Om minskar till
-
 .
.
Standard hyperbolastisk funktion av typ II definieras som
-
 .
.
Funktion H3
Hyperbolastisk hastighetsekvation av typ III betecknas med H3 och har formen
-
 ,
,
där  > 0. Parametern representerar bärförmågan, och parametrarna
> 0. Parametern representerar bärförmågan, och parametrarna 
 och bestämmer gemensamt tillväxttakten. Parametern representerar accelerationen av tidsskalan, medan storleken på representerar avståndet från en symmetrisk sigmoidal kurva. Lösningen på differentialekvationen för typ III är
och bestämmer gemensamt tillväxttakten. Parametern representerar accelerationen av tidsskalan, medan storleken på representerar avståndet från en symmetrisk sigmoidal kurva. Lösningen på differentialekvationen för typ III är
-
 ,
,
med initialvillkoret  kan vi uttrycka som
kan vi uttrycka som
-
 .
.
Den hyperbolastiska fördelningen av typ III är en treparameterfamilj av kontinuerliga sannolikhetsfördelningar med skalparametrar > 0, och ≥ 0 och parametern som form parameter . När parametern = 0 reduceras den hyperbolastiska fördelningen av typ III till weibullfördelningen . Den hyperbolastiska kumulativa fördelningsfunktionen för typ III ges av
-
 ,
,
och dess motsvarande sannolikhetstäthetsfunktion är
-
 .
.
Riskfunktionen  (eller felfrekvensen) ges av
(eller felfrekvensen) ges av

Överlevnadsfunktionen  { ges av
{ ges av

Standardfunktionen för hyperbolastisk kumulativ distribution av typ III definieras som
-
 ,
,
och dess motsvarande sannolikhetstäthetsfunktion är
-
 .
.
Egenskaper
Om man vill beräkna punkten där populationen når en procentandel av sin bärförmåga , då kan man lösa ekvationen

för , där  . Till exempel kan halvpunkten hittas genom att sätta
. Till exempel kan halvpunkten hittas genom att sätta  .
.
Ansökningar

3D hyperbolastisk graf över växtplanktonbiomassa som en funktion av näringsämneskoncentration och tid
Enligt stamcellsforskare vid McGowan Institute for Regenerative Medicine vid University of Pittsburgh, "är en nyare modell [kallad hyperbolastisk typ III eller] H3 en differentialekvation som också beskriver celltillväxten. Denna modell möjliggör mycket mer variation och har har visat sig bättre förutsäga tillväxt."
De hyperbolastiska tillväxtmodellerna H1, H2 och H3 har använts för att analysera tillväxten av solid Ehrlich-karcinom med användning av en mängd olika behandlingar.
Inom djurvetenskapen har hyperbolastiska funktioner använts för att modellera broilerkycklingstillväxt. Den hyperbolastiska modellen av typ III användes för att bestämma storleken på det återhämtande såret.
Inom området för sårläkning representerar de hyperbolastiska modellerna exakt läkningens tidsförlopp. Sådana funktioner har använts för att undersöka variationer i läkningshastigheten mellan olika typer av sår och i olika stadier i läkningsprocessen med hänsyn till områdena spårämnen, tillväxtfaktorer, diabetiska sår och näring.
En annan tillämpning av hyperbolastiska funktioner är inom området för den stokastiska diffusionsprocessen , vars medelfunktion är en hyperbolastisk kurva. Processens huvudsakliga egenskaper studeras och den maximala sannolikhetsuppskattningen för processens parametrar beaktas. För detta ändamål tillämpas den eldfluga metaheuristiska optimeringsalgoritmen efter att ha begränsat det parametriska utrymmet genom en stegvis procedur. Några exempel baserade på simulerade provvägar och verkliga data illustrerar denna utveckling. En provbana för en diffusionsprocess modellerar banan för en partikel som är inbäddad i en strömmande vätska och utsatts för slumpmässiga förskjutningar på grund av kollisioner med andra partiklar, vilket kallas Brownsk rörelse . Den hyperbolastiska funktionen av typ III användes för att modellera proliferationen av både vuxna mesenkymala och embryonala stamceller ; och den hyperbolastiska blandade modellen av typ II har använts vid modellering av livmoderhalscancerdata . Hyperbolastiska kurvor kan vara ett viktigt verktyg för att analysera celltillväxt, anpassning av biologiska kurvor, tillväxten av växtplankton och momentan mognadshastighet.
Inom skogsekologi och skogsskötsel har hyperbolastiska modeller tillämpats för att modellera förhållandet mellan DBH och höjd.
Den multivariabla hyperbolastiska modellen typ III har använts för att analysera tillväxtdynamiken hos växtplankton med hänsyn till koncentrationen av näringsämnen.
Hyperbolastiska regressioner
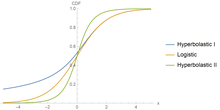
Kumulativ distributionsfunktion för Hyperbolastic Typ I, Logistic och Hyperbolastic Typ II
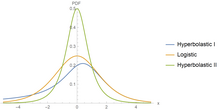
PDF av H1, Logistic och H2
Hyperbolastiska regressioner är statistiska modeller som använder standard hyperbolastiska funktioner för att modellera en dikotom eller multinomial utfallsvariabel. Syftet med hyperbolastisk regression är att förutsäga ett utfall med hjälp av en uppsättning förklarande (oberoende) variabler. Dessa typer av regressioner används rutinmässigt inom många områden, inklusive medicinsk, folkhälsa, tandvård, biomedicin samt social-, beteende- och ingenjörsvetenskap. Till exempel har binär regressionsanalys använts för att förutsäga endoskopiska lesioner vid järnbristanemi . Dessutom användes binär regression för att skilja mellan malign och benign adnexal massa före operation.
Den binära hyperbolastiska regressionen av typ I
Låt  vara en binär utfallsvariabel som kan anta ett av två ömsesidigt uteslutande värden, framgång eller misslyckande. Om vi kodar framgång som
vara en binär utfallsvariabel som kan anta ett av två ömsesidigt uteslutande värden, framgång eller misslyckande. Om vi kodar framgång som  och misslyckande som
och misslyckande som  , då för parametern
, då för parametern  , den hyperbolastiska framgångssannolikheten av typ I med ett urval av storleken
, den hyperbolastiska framgångssannolikheten av typ I med ett urval av storleken  som funktion av parametern och parametervektorn
som funktion av parametern och parametervektorn  givet en
givet en  -dimensionell vektor av förklarande variabler definieras som
-dimensionell vektor av förklarande variabler definieras som  , där
, där  , ges av
, ges av
-
 .
.
Oddsen för framgång är förhållandet mellan sannolikheten för framgång och sannolikheten för misslyckande. För binär hyperbolastisk regression av typ I betecknas oddsen för framgång med  och uttrycks med ekvationen
och uttrycks med ekvationen
-
 .
.
Logaritmen för kallas logit för binär hyperbolastisk regression av typ I. Logittransformationen betecknas med  och kan skrivas som
och kan skrivas som
-
![{\displaystyle L_{H1}=\beta _{0}+\sum _{s=1}^{p}{\beta _{s}x_{is}}+\theta \operatorname {arsinh} [\beta _{0}+\sum _{s=1}^{p}{\beta _{s}x_{is}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c8dc6a8ac2eec7c173ca3a322c514202094da9b6) .
.
Shannon-information för binär hyperbolastisk typ I (H1)
Shannon -informationen för slumpvariabeln definieras som

där basen för logaritmen  och
och  . För binärt utfall
. För binärt utfall  lika med
lika med  .
.
ges informationen 
-
 ,
,
där  , och
, och  är
är  indata. För ett slumpmässigt urval av binära utfall av storleken kan den genomsnittliga empiriska informationen för hyperbolastisk H1 uppskattas med
indata. För ett slumpmässigt urval av binära utfall av storleken kan den genomsnittliga empiriska informationen för hyperbolastisk H1 uppskattas med
-
 ,
,
där  och
och  är indata för
är indata för  observationen.
observationen.
Information Entropi för hyperbolastisk H1
Informationsentropi mäter förlusten av information i ett överfört meddelande eller en signal. I maskininlärningsapplikationer är det antalet bitar som krävs för att sända en slumpmässigt vald händelse från en sannolikhetsfördelning. För en diskret slumpvariabel definieras informationsentropin 

där  är sannolikhetsmassfunktionen för slumpvariabeln .
är sannolikhetsmassfunktionen för slumpvariabeln .
Informationsentropin är den matematiska förväntan av med avseende på sannolikhetsmassfunktionen . Informationsentropin har många tillämpningar inom maskininlärning och artificiell intelligens såsom klassificeringsmodellering och beslutsträd. För den hyperbolastiska H1 är entropin lika med
![{\displaystyle {\begin{aligned}H&=-\sum _{y\in \{0,1\}}{P(Y=y;\mathbf {x} ,{\boldsymbol {\beta }})log_{b}(P(Y=y;\mathbf {x} ,{\boldsymbol {\beta }}))}\\&=-[\pi (\mathbf {x} ;{\boldsymbol {\beta }})\ log_{b}(\pi (\mathbf {x} ;{\boldsymbol {\beta }})+(1-\pi (\mathbf {x} ;{\boldsymbol {\beta }}))log_{b}(1-\pi (\mathbf {x} ;{\boldsymbol {\beta }}))]\\&={log}_{b}(1+e^{-Z-\theta \operatorname {arsinh} (Z)})-{\frac {e^{-Z-\theta \operatorname {arsinh} (Z)}{log}_{b}(e^{-Z-\theta \operatorname {arsinh} (Z)})}{1+e^{-Z-\theta \operatorname {arsinh} (Z)}}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b6fbee70171730bdd0b7f63a3f0e340e2821e163)
Den uppskattade medelentropin för hyperbolastisk H1 betecknas med  och ges av
och ges av
![{\displaystyle {\bar {H}}={\frac {1}{n}}\sum _{i=1}^{n}{[log_{b}(1+e^{{-Z}_{i}-\theta \operatorname {arsinh} (Z_{i})})-}{\frac {e^{{-Z}_{i}-\theta \operatorname {arsinh} (Z_{i})}\ {log}_{b}(e^{{-Z}_{i}-\theta \operatorname {arsinh} ((Z_{i})})}{1+e^{{-Z}_{i}-\theta \operatorname {arsinh} (Z_{i})}}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a82ca0676b5f24a68b2f8e0bd0beabc9c3e63205)
Binär korsentropi för hyperbolastisk H1
Den binära korsentropin jämför den observerade  med de förutsagda sannolikheterna. Den genomsnittliga binära korsentropin för hyperbolastisk H1 betecknas med
med de förutsagda sannolikheterna. Den genomsnittliga binära korsentropin för hyperbolastisk H1 betecknas med  och är lika med
och är lika med
![{\displaystyle {\begin{aligned}{\overline {C}}&=-{\frac {1}{n}}\sum _{i=1}^{n}{{[y}_{i}log_{b}(\pi (x_{i};{\boldsymbol {\beta }}))+}{(1-y}_{i})log_{b}(1-\pi (x_{i};{\boldsymbol {\beta }}))]\\&={\frac {1}{n}}\sum _{i=1}^{n}{[log_{b}(1+e^{{-Z}_{i}-\theta \operatorname {arsinh} (Z_{i})})-}{(1-y}_{i})log_{b}(e^{{-Z}_{i}-\theta \operatorname {arsinh} (Z_{i})})]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/44089bb724a6349571bcc691b998c4bc25a2b18b)
Kullback-Leibler-divergens för hyperbolastisk H1
Kullback-Leibler divergens är ett olikhetsmått som uppskattar antalet bitar som krävs för att representera ett meddelande när hyperbolastisk sannolikhetsfördelning H1 används och är lika med

och medelvärdet för Kullback-Leibler Divergence  är
är
![{\displaystyle {\overline {KLD}}={\frac {1}{n}}\sum _{i=1}^{n}{[{\frac {e^{{-Z}_{i}-\theta \operatorname {arsinh} (Z_{i})}\ {log}_{b}(e^{{-Z}_{i}-\theta \operatorname {arsinh} (Z_{i})})}{1+e^{{-Z}_{i}-\theta \operatorname {arsinh} (Z_{i})}}}-}{(1-y}_{i})log_{b}(e^{{-Z}_{i}-\theta \operatorname {arsinh} (Z_{i})})]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/58425c40eb8467f131b537b352b9de6a27fccba8)
Den binära hyperbolastiska regressionen av typ II
Den hyperbolastiska regressionen av typ II är en alternativ metod för analys av binära data med robusta egenskaper. För den binära utfallsvariabeln är den hyperbolastiska framgångssannolikheten för typ II en funktion av en -dimensionell vektor av förklarande variabler  ges av
ges av
-
![{\displaystyle \pi (\mathbf {x} _{i};{\boldsymbol {\beta }})=P(y_{i}=1|\mathbf {x} _{i};{\boldsymbol {\beta }})={\frac {1}{1+\operatorname {arsinh} [e^{-(\beta _{0}+\sum _{s=1}^{p}{\beta _{s}x_{is}})}]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4e64a00935cd8a02dfd1e5e226e7124f9a52d3ac) ,
,
För den binära hyperbolastiska regressionen av typ II betecknas oddsen för framgång med  och definieras som
och definieras som
![{\displaystyle Odds_{H2}={\frac {1}{\operatorname {arsinh} [e^{-(\beta _{0}+\sum _{s=1}^{p}{\beta _{s}x_{is}})}]}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/45e4274ceab088ef883aa75368bde67263146083)
Logit-transformationen  ges av
ges av
![{\displaystyle L_{H2}=-\log {(\operatorname {arsinh} [e^{-(\beta _{0}+\sum _{s=1}^{p}{\beta _{s}x_{is}})}])}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3e6da0d4c14f3846b73057410eabde76a3a92a3a)
Shannon-information för binär hyperbolastisk typ II (H2)
ges Shannon-informationen

där , och är indata. För ett slumpmässigt urval av binära utfall av storleken uppskattas den genomsnittliga empiriska informationen för hyperbolastisk H2 med

där och är indata för observationen.
Information Entropi för hyperbolastisk H2
För den hyperbolastiska H2 är informationsentropin lika med
![{\displaystyle {\begin{aligned}H&=-\sum _{y\in \{0,1\}}{P(Y=y;\mathbf {x} ,{\boldsymbol {\beta }})log_{b}(P(Y=y;\mathbf {x} ,{\boldsymbol {\beta }}))}\\&=-[\pi (\mathbf {x} ;{\boldsymbol {\beta }})\ log_{b}(\pi (\mathbf {x} ;{\boldsymbol {\beta }}))+(1-\pi (\mathbf {x} ;{\boldsymbol {\beta }}))log_{b}(1-\pi (\mathbf {x} ;{\boldsymbol {\beta }}))]\\&=log_{b}(1+arsinh(e^{-Z}))-{\frac {arsinh(e^{-Z})log_{b}(arsinh(e^{-Z}))}{1+arsinh(e^{-Z})}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/335d21ba07626c251d38cd081e2cc8196a84db5a)
och den uppskattade medelentropin för hyperbolastisk H2 är
![{\displaystyle {\bar {H}}={\frac {1}{n}}\sum _{i=1}^{n}{[log_{b}(1+{arsinh(e}^{{-Z}_{i}}))-}{\frac {{arsinh(e}^{{-Z}_{i}})\ {log}_{b}{(arsinh(e}^{{-Z}_{i}}))}{1+{arsinh(e}^{{-Z}_{i}})}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fa109fe4690aaddae176c908288668ba84bf67cf)
Binär korsentropi för hyperbolastisk H2
Den genomsnittliga binära korsentropin för hyperbolastisk H2 är
![{\displaystyle {\begin{aligned}{\overline {C}}&=-{\frac {1}{n}}\sum _{i=1}^{n}{{[y}_{i}log_{b}(\pi (x_{i};\beta ))+}{(1-y}_{i})log_{b}(1-\pi (x_{i};\beta ))]\\&={\frac {1}{n}}\sum _{i=1}^{n}{[log_{b}(1+{arsinh(e}^{{-Z}_{i}}))-}{(1-y}_{i})log_{b}({arsinh(e}^{{-Z}_{i}}))]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6fd0cb31dc57781a5279efb73cb354fc69d759ee)
Kullback-Leibler-divergens för hyperbolastisk H2
För hyperbolastisk H2 är Kullback-Leibler-divergensen lika med

och medelvärdet för Kullback-Leibler Divergence är
![{\displaystyle {\overline {KLD}}={\frac {1}{n}}\sum _{i=1}^{n}{[{\frac {{arsinh(e}^{{-Z}_{i}})\ {log}_{b}{(arsinh(e}^{{-Z}_{i}}))}{1+{arsinh(e}^{{-Z}_{i}})}}-}{(1-y}_{i})log_{b}({arsinh(e}^{{-Z}_{i}}))]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3c6a573604fd6b9f72449b09d5ea0441a7411053)
Parameteruppskattning för binär hyperbolastisk regression av typ I och II
Uppskattningen av parametervektorn  kan erhållas genom att maximera log-likelihood-funktionen
kan erhållas genom att maximera log-likelihood-funktionen
![{\displaystyle {\hat {\beta }}={\underset {\boldsymbol {\beta }}{\operatorname {argmax} }}{\sum _{i=1}^{n}[y_{i}ln(\pi (\mathbf {x} _{i};{\boldsymbol {\beta }}))+(1-y_{i})ln(1-\pi (\mathbf {x} _{i};{\boldsymbol {\beta }}))]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5235e950a0be6ac2bc01d9ec436b0157feaa2181)
där  definieras enligt en av de två typerna av hyberbolastiska funktioner som används.
definieras enligt en av de två typerna av hyberbolastiska funktioner som används.
Multinomial hyperbolastisk regression av typ I och II
Generaliseringen av den binära hyperbolastiska regressionen till multinomial hyperbolastisk regression har en svarsvariabel  för individuella
för individuella  med
med  -kategorier (dvs
-kategorier (dvs  . När
. När  reduceras denna modell till en binär hyperbolastisk regression. För varje , bildar vi
reduceras denna modell till en binär hyperbolastisk regression. För varje , bildar vi  indikatorvariabler
indikatorvariabler  var
var
-
 ,
,
vilket betyder att  när svaret är i kategori
när svaret är i kategori  och
och  annars.
annars.
Definiera parametervektor  i ett
i ett  -dimensionellt euklidiskt utrymme och
-dimensionellt euklidiskt utrymme och  .
.
Använder kategori 1 som referens och  som motsvarande sannolikhetsfunktion , definieras den multinomiala hyperbolastiska regressionen av typ I-sannolikheter som
som motsvarande sannolikhetsfunktion , definieras den multinomiala hyperbolastiska regressionen av typ I-sannolikheter som
![{\displaystyle \pi _{1}(\mathbf {x} _{i};{\boldsymbol {\beta }})=P(y_{i}=1|\mathbf {x} _{i};{\boldsymbol {\beta }})={\frac {1}{1+\sum _{s=1}^{k-1}e^{-\eta _{s}(\mathbf {x} _{i};{\boldsymbol {\beta }})-\theta \operatorname {arsinh} [\eta _{s}(\mathbf {x} _{i};{\boldsymbol {\beta }})]}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fcf67a2481706548b733217661be83e1bbc1f6ba)
och för  ,
,
![{\displaystyle \pi _{j}(\mathbf {x} _{i};{\boldsymbol {\beta }})=P(y_{i}=j|\mathbf {x} _{i};{\boldsymbol {\beta }})={\frac {e^{-\eta _{j}(\mathbf {x} _{i};{\boldsymbol {\beta }})-\theta \operatorname {arsinh} [\eta _{j}(\mathbf {x} _{i};{\boldsymbol {\beta }})]}}{1+\sum _{s=1}^{k-1}e^{-\eta _{s}(\mathbf {x} _{i};{\boldsymbol {\beta }})-\theta \operatorname {arsinh} [\eta _{s}(\mathbf {x} _{i};{\boldsymbol {\beta }})]}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6b14a738fc2cc1be0e7aea69315af8ad63923e97)

På liknande sätt har vi för den multinomiala hyperbolastiska regressionen av typ II
![{\displaystyle \pi _{1}(\mathbf {x} _{i};{\boldsymbol {\beta }})=P(y_{i}=1|\mathbf {x} _{i};{\boldsymbol {\beta }})={\frac {1}{1+\sum _{s=1}^{k-1}arsinh[e^{-\eta _{s}(\mathbf {x} _{i};{\boldsymbol {\beta }})}]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6954129f101f87783dffaa91fc7f34f2e55ccb34)
och för ,
![{\displaystyle \pi _{j}(\mathbf {x} _{i};{\boldsymbol {\beta }})=P(y_{i}=j|\mathbf {x} _{i};{\boldsymbol {\beta }})={\frac {arsinh[e^{-\eta _{j}(\mathbf {x} _{i};{\boldsymbol {\beta }})}]}{1+\sum _{s=1}^{k-1}arsinh[e^{-\eta _{s}(\mathbf {x} _{i};{\boldsymbol {\beta }})}]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/29fb74710a9ed65c70670fe71b7ab2839453066f)
Valet av  på valet av hyperbolastisk H1 eller H2 .
på valet av hyperbolastisk H1 eller H2 .
Shannon Information för multiklass hyperbolastisk H1 eller H2
För multiklassen  är Shannon-informationen
är Shannon-informationen 
-
 .
.
För ett slumpmässigt urval av storleken kan den empiriska multiklassinformationen uppskattas med
-
 .
.
Flerklassentropi i informationsteori
För en diskret slumpvariabel definieras multiklassinformationsentropin som
där är sannolikhetsmassfunktionen för multiklass-slumpvariabeln .
För hyperbolastiska H1 eller H2 är multiklassentropin lika med
![{\displaystyle H=-\sum _{j=1}^{k}{[\pi _{j}(\mathbf {x} ;{\boldsymbol {\beta }})log_{b}(\pi _{j}(\mathbf {x} ;{\boldsymbol {\beta }}))]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/87f7c29296f216551a4c08412fc9762ee9f40d2f)
Den uppskattade genomsnittliga multiklassentropin  är lika med
är lika med
![{\displaystyle {\overline {H}}=-{\frac {1}{n}}\sum _{i=1}^{n}{\sum _{j=1}^{k}{[\pi _{j}(\mathbf {x_{i}} ;{\boldsymbol {\beta }})log_{b}(\pi _{j}(\mathbf {x_{i}} ;{\boldsymbol {\beta }}))]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1958159449968b0442fcad989e428b0c7896f8f0)
Multiclass Cross-entropy för hyperbolastisk H1 eller H2
Multiclass cross-entropy jämför den observerade multiklassutdatan med de förutsagda sannolikheterna. För ett slumpmässigt urval av flerklassresultat av storleken kan den genomsnittliga multiklass-korsentropin för hyperbolastisk H1 eller H2 uppskattas med
![{\displaystyle {\overline {C}}=-{\frac {1}{n}}\sum _{i=1}^{n}{\sum _{j=1}^{k}{[y_{ij}log_{b}(\pi _{j}(\mathbf {x_{i}} ;{\boldsymbol {\beta }}))]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fe7a5f5fc2f37db63d1d4cd2f1c572f7d40191dd)
Kullback-Leibler Divergence för multiklass hyperbolastisk H1 eller H2
Den genomsnittliga Kullback-Leibler-divergensen för multiklasshyperbolastisk H1 eller H2 är lika med
![{\displaystyle {\overline {KLD}}=-{\frac {1}{n}}\sum _{i=1}^{n}{\sum _{j=1}^{k}{[(y_{ij}-\pi _{j}(\mathbf {x_{i}} ;{\boldsymbol {\beta }}))log_{b}(\pi _{j}(\mathbf {x_{i}} ;{\boldsymbol {\beta }}))]}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0b6a7ccd7892aab7aa56b3ca24eb4fd3dfddb357)
Loggoddsen för medlemskap i kategori kontra referenskategori 1, betecknad med  , är lika med
, är lika med
![{\displaystyle \eta _{j}(\mathbf {x} _{i};{\boldsymbol {\beta }})=ln[{\frac {\pi _{j}(\mathbf {x} _{i};{\boldsymbol {\beta }})}{\pi _{1}(\mathbf {x} _{i};{\boldsymbol {\beta }})}}]=\beta _{j0}+\beta _{j1}x_{i1}+\ldots +\beta _{jp}x_{ip}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c0cd1f989a4afcffc98150db2c635d955e4a095a)
där  och
och  . Den uppskattade parametermatrisen
. Den uppskattade parametermatrisen  för multinomial hyperbolastisk regression erhålls genom att maximera log-likelihood-funktionen. De maximala sannolikhetsuppskattningarna för parametermatrisen är
för multinomial hyperbolastisk regression erhålls genom att maximera log-likelihood-funktionen. De maximala sannolikhetsuppskattningarna för parametermatrisen är
![{\displaystyle {\boldsymbol {\hat {\beta }}}={\underset {\boldsymbol {\beta }}{\operatorname {argmax} }}{\sum _{i=1}^{n}(y_{i1}ln[\pi _{1}(\mathbf {x} _{i};{\boldsymbol {\beta }})]+y_{i2}ln[\pi _{2}(\mathbf {x} _{i};{\boldsymbol {\beta }})]+\ldots +y_{ik}ln[\pi _{k}(\mathbf {x} _{i};{\boldsymbol {\beta }})])}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d4e5145d7f108428d98c9a82d8a1c0b3f652c2da)









