Neyman-konstruktion , uppkallad efter Jerzy Neyman , är en frekventistisk metod för att konstruera ett intervall på en konfidensnivå  så att om vi upprepar experimentet många gånger kommer intervallet att innehålla det sanna värdet av någon parameter a bråkdel
så att om vi upprepar experimentet många gånger kommer intervallet att innehålla det sanna värdet av någon parameter a bråkdel  av tiden.
av tiden.
Teori
Antag  är slumpvariabler med gemensam pdf
är slumpvariabler med gemensam pdf  , vilket beror på k okända parametrar. För enkelhetens skull, låt
, vilket beror på k okända parametrar. För enkelhetens skull, låt 
 vara sampelutrymmet som definieras av de n slumpvariablerna och definiera därefter en provpunkt i sampelutrymmet som Neyman föreslog ursprungligen att definiera två funktioner
vara sampelutrymmet som definieras av de n slumpvariablerna och definiera därefter en provpunkt i sampelutrymmet som Neyman föreslog ursprungligen att definiera två funktioner  och
och  så att för valfri provpunkt,
så att för valfri provpunkt,  ,
,
-


- L och U är enkelvärderade och definierade.
Givet en observation,  , är sannolikheten att
, är sannolikheten att  ligger mellan
ligger mellan  och
och  definieras som
definieras som  med sannolikheten
med sannolikheten  eller
eller  . Dessa beräknade sannolikheter misslyckas med att dra meningsfulla slutsatser om eftersom sannolikheten helt enkelt är noll eller enhet. Vidare, under den frekventistiska konstruktionen är modellparametrarna okända konstanter och får inte vara slumpvariabler. Till exempel om
. Dessa beräknade sannolikheter misslyckas med att dra meningsfulla slutsatser om eftersom sannolikheten helt enkelt är noll eller enhet. Vidare, under den frekventistiska konstruktionen är modellparametrarna okända konstanter och får inte vara slumpvariabler. Till exempel om  , då
, då  . På samma sätt, om
. På samma sätt, om  , då
, då 
Som Neyman beskriver i sin uppsats från 1937, anta att vi betraktar alla punkter i provutrymmet, det vill säga , som är ett system av slumpvariabler som definieras av den gemensamma pdf-filen beskrivs ovan. Eftersom  och
och  är funktioner av är de också slumpvariabler och man kan undersöka innebörden av följande sannolikhetssats:
är funktioner av är de också slumpvariabler och man kan undersöka innebörden av följande sannolikhetssats:
- Under den frekventistiska konstruktionen är modellparametrarna okända konstanter och får inte vara slumpvariabler. Om man betraktar alla provpunkter i provrummet som slumpvariabler definierade av den gemensamma pdf-filen ovan, det vill säga alla
 kan det visas att och är funktioner av slumpvariabler och därmed slumpvariabler. Därför kan man titta på sannolikheten för
kan det visas att och är funktioner av slumpvariabler och därmed slumpvariabler. Därför kan man titta på sannolikheten för  och
och  för några . Om
för några . Om  är det sanna värdet av , kan vi definiera och så att sannolikheten
är det sanna värdet av , kan vi definiera och så att sannolikheten  och
och  är lika med fördefinierad konfidensnivå
är lika med fördefinierad konfidensnivå  .
.
Det vill säga  där
där  och och är de övre och nedre konfidensgränserna för
och och är de övre och nedre konfidensgränserna för
Täckningssannolikhet
Täckningssannolikheten ,  , för Neyman-konstruktion är frekvensen av experiment där konfidensintervallet innehåller det faktiska värdet av intresse . I allmänhet är täckningssannolikheten inställd på
, för Neyman-konstruktion är frekvensen av experiment där konfidensintervallet innehåller det faktiska värdet av intresse . I allmänhet är täckningssannolikheten inställd på  konfidens. För Neyman-konstruktion är täckningssannolikheten satt till något värde där
konfidens. För Neyman-konstruktion är täckningssannolikheten satt till något värde där  . Detta värde talar om hur säkra vi är på att det sanna värdet kommer att finnas i intervallet.
. Detta värde talar om hur säkra vi är på att det sanna värdet kommer att finnas i intervallet.
Genomförande
En Neyman-konstruktion kan utföras genom att utföra flera experiment som konstruerar datamängder som motsvarar ett givet värde på parametern. Experimenten är utrustade med konventionella metoder och utrymmet för anpassade parametervärden utgör det band som konfidensintervallet kan väljas från.
Klassiskt exempel
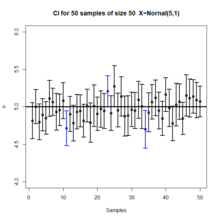
Plotta med 50 konfidensintervall från 50 sampel genererade från en normalfördelning.
Antag att  , där
, där  och
och  är okända konstanter där vi vill uppskatta . Vi kan definiera (2) enstaka värdefunktioner, och , definierade av processen ovan så att givet en fördefinierad konfidensnivå, och slumpmässigt urval
är okända konstanter där vi vill uppskatta . Vi kan definiera (2) enstaka värdefunktioner, och , definierade av processen ovan så att givet en fördefinierad konfidensnivå, och slumpmässigt urval 


där  är standardfelet och urvalets medelvärde och standardavvikelse är:
är standardfelet och urvalets medelvärde och standardavvikelse är:


Faktorn  följer en t- fördelning med (n-1) frihetsgrader, ~t
följer en t- fördelning med (n-1) frihetsgrader, ~t 
Ett annat exempel

 är iid slumpvariabler, och låt . Antag
är iid slumpvariabler, och låt . Antag  . Nu för att konstruera ett konfidensintervall med konfidensnivå. Vi vet att
. Nu för att konstruera ett konfidensintervall med konfidensnivå. Vi vet att  är tillräckligt för
är tillräckligt för  . Så,
. Så,



Detta ger ett  konfidensintervall för där,
konfidensintervall för där,

-
 .
.
Se även
